
Иногда нужно исключить определенный контент WordPress или файлы из индексирования в результатах поиска Google.
Индексация Google обычно относится к процессу добавления новых веб-страниц, включая цифровой контент (документы, видео, изображения), и хранения их в своей базе данных. Другими словами, чтобы контент вашего сайта появился в результатах поиска Google, его сначала нужно сохранить в индексе поисковой системы.
Google может индексировать все эти цифровые страницы и контент, используя своих пауков, сканеров или ботов, которые постоянно сканируют различные веб-сайты в Интернете. Они следуют инструкциям владельцев веб-сайтов о том, что сканировать, а что следует игнорировать во время сканирования.
Зачем нужно индексировать сайты?
В цифровую эпоху трудно перемещаться по миллиардам веб-сайтов, находя определенный контент. Это будет намного проще сделать, если есть инструмент, способный показать нам отсортированную, полезную и актуальную для нас информацию. Именно этим и занимается поисковая система Google, ранжируя сайты в результатах поиска.
Индексирование – неотъемлемая часть работы поисковых систем. Оно помогает определить слова и выражения, которые лучше всего описывают страницу и в целом способствует ранжированию страницы и веб-сайта. Чтобы появиться на первой странице Google, ваш сайт, включая веб-страницы и цифровые файлы (видео, изображения и документы), сначала должен быть проиндексирован.
Используя фокусное ключевое слово и другие ключи, сайты могут занимать более высокие позиции в поиске. Это открывает двери для новых посетителей, подписчиков и потенциальных клиентов вашего сайта и бизнеса.
Также читайте: Как добавить поддержку IndexNow на свой WordPress-сайт и ускорить с его помощью индексацию.
Зачем и как исключать контент из поиска Google?
На любом веб-ресурсе есть страницы, целые разделы или файлы сайта, которые не нужно показывать в результатах поиска. Часто это необходимо для обеспечения безопасности и гарантии конфиденциальности. Без паролей или аутентификации частный контент подвергается риску раскрытия и несанкционированного доступа, если ботам дать полную свободу действий над папками и файлами вашего сайта.
В начале 2000-х хакеры использовали Google для отображения информации о кредитных картах с веб-сайтов. Этот недостаток безопасности использовался многими хакерами для кражи информации о картах с веб-сайтов электронной коммерции.
Подобные случаи происходят в интернете и могут привести к потере продаж и доходов для владельцев бизнеса. Для корпоративных сайтов, электронных магазинов и сайтов-сообществ критически важно сначала блокировать индексацию конфиденциального контента и частных файлов, а затем создать надежную систему аутентификации пользователей.
Давайте посмотрим, как можно управлять контентом и файлами относительно попадания их в индекс и поиск Google.
Также читайте: Лучшие бесплатные плагины Гугл.
1. Использование robots.txt для изображений
robots.txt – это файл, расположенный в корне вашего сайта, предоставляющий ботам поисковых систем инструкции о том, что сканировать, а что нет. Файл обычно используется для управления трафиком обхода веб-сканерами (мобильными и настольными). С его помощью можно также запретить появление изображений в результатах поиска Google.
Для сайтов WordPress файл robots.txt может содержать такие инструкции:
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/
Первая инструкция означает, что сайт открыт для всех ботов, которые будут следовать всем инструкциям, приведенным ниже. Две остальные – запретить индексировать папки wp-admin и wp-includes.
Как исключить медиафайлы из поиска?
robots.txt также может быть использован, чтобы заблокировать обход некоторых форматов файлов (например, PDF, GIF, JPG, MP4). Для этого нужно добавить следующие инструкции.
Для PDF:
User-agent: * Disallow: /pdfs/ Disallow: *.pdf$
JPG:
User-agent: Googlebot-Image Disallow: /images/cats.jpg
GIF:
User-agent: Googlebot-Image Disallow: /*.gif$
Вышеприведенные фрагменты кода просто исключают ваш контент из индексирования сторонними ресурсами, такими как Google. Но они все же доступны по URL-ссылкам. Чтобы запретить к ним доступ вообще, нужно будет использовать другие методы (например, с помощью плагинов ограничения контента Restricted Site Access, Ultimate Member или Users Ultra Membership).
Поисковый агент Googlebot-Image может быть использован для блокировки конкретных расширений изображений от появления в результатах поиска картинок. Если нужно исключить их из всех поисковых запросов (веб-поиска и изображений), рекомендуется использовать пользовательский агент Googlebot.
Также можете использовать другие Google-агенты для исключения типов файлов. Например, Googlebot-Video применяется для видеороликов в разделе Google Видео.
Имейте в виду, что robots.txt не подходит для блокировки конфиденциальных файлов и содержимого из-за своих ограничений:
- он дает инструкции ботам, которые могут быть проигнорированы поисковой системой;
- robots.txt не закрывает доступ к страницам и файлам вашего сайта;
- поисковые системы смогут найти и проиндексировать заблокированные страницы и содержимое, если они связаны с другими веб-сайтами и источниками;
- robots.txt доступен для всех по ссылке https://site.ru/robots.txt.
Чтобы заблокировать индексирование поиска и более эффективно защитить вашу личную информацию, используйте следующие методы.
Самый лучший и корректный файл robots.txt для вашего WordPress-сайта создает плагин Clearfy Pro. Разработчики перерыли массу инструкций, чтобы на выходе получить максимально качественный роботс.
2. Использование метатега noindex для страниц
Использование метатега noindex – это правильный и эффективный способ блокировать поисковую индексацию конфиденциального контента на вашем сайте. В отличие от robots.txt, метатег размещается в разделе <head> веб-страницы и имеет вид:
<html> <head> <title>...</title> <meta name="robots" content="noindex"> </head>
Любая страница с этой инструкцией в заголовке не будет отображаться в результатах поиска Google. Другие директивы, такие как nofollow и notranslate, также могут использоваться, чтобы запретить сканировать ссылки и предлагать перевод этой страницы соответственно.
Можно также закрыть доступ нескольким конкретным поисковым роботам:
<html> <head> <title>...</title> <meta name="googlebot" content="nofollow"> <meta name="googlebot-news" content="nosnippet"> </head>
Добавить этот код на сайт можно двумя способами. Первый вариант – создать дочернюю тему WordPress, а затем в файле functions.php использовать хук WordPress wp_head для вставки noindex или любых других мета-тегов.
Если вы не знаете, как редактировать functions.php, то в этом случае Вам поможет плагин ProFunctions.
Ниже приведен пример того, как добавить noindex на страницу входа:
function wpschool_login_page_noindex() {
if ( is_page( 'login' ) ) {
echo '<meta name="robots" content="noindex">';
}
}
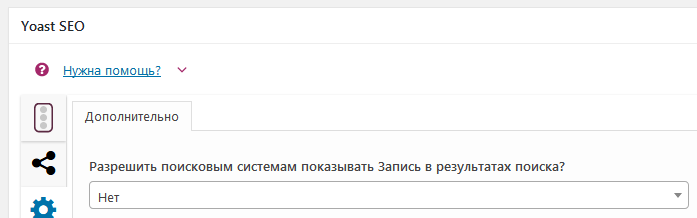
add_action( 'wp_head', 'wpschool_login_page_noindex' ); Второй способ – использовать SEO-плагин для управления видимостью страницы. Например, в Yoast SEO вы можете перейти в раздел дополнительных настроек на странице/записи и просто выбрать Нет в настройке Разрешить поисковым системам показывать Запись в результатах поиска?
3. Использование заголовка HTTP X-Robots-Tag для других файлов
X-Robots-Tag дает больше гибкости, чтобы блокировать индексацию поиска контента и файлов. В частности, по сравнению с метатегом noindex, он может использоваться в качестве ответа заголовка HTTP для любых заданных URL-адресов. Например, вы можете использовать X-Robots-Tag для файлов изображений, видео и документов, где невозможно использовать мета-теги роботов.
К примеру, запретим всем роботам индексировать изображения в формате JPEG:
HTTP/1.1 200 OK Content-type: image/jpeg Date: Sat, 30 Nov 2018 01:02:09 GMT (…) X-Robots-Tag: noindex, nofollow (…)
Также можно указать конкретных роботов:
HTTP/1.1 200 OK Date: Tue, 30 Nov 2018 01:02:09 GMT (…) X-Robots-Tag: googlebot: nofollow X-Robots-Tag: bingbot: noindex X-Robots-Tag: otherbot: noindex, nofollow (…)
Важно отметить, что поисковые роботы обнаруживают мета-теги и HTTP-заголовки X-Robots-Tag во время сканирования. Поэтому, если вы хотите, чтобы эти боты следовали вашим инструкциям и не индексировали конфиденциальный контент и документы, вы не должны останавливать обход этих URL-адресов страниц и файлов.
Если они сканируют с помощью robots.txt, ваши инструкции по индексации не будут прочитаны, а значит, проигнорированы. В результате, если другие веб-сайты ссылаются на ваш контент и документы, они все равно будут индексироваться Google и другими поисковыми системами.
4. С помощью правил .htaccess для серверов Apache
Вы также можете добавить заголовок HTTP X-Robots-Tag в .htaccess-файл, блокирующий поисковые роботы от индексации страниц и цифрового содержимого вашего веб-сайта, размещенного на сервере Apache. В отличие от метатегов noindex, правила в .htaccess могут применяться ко всему сайту или к определенной папке. Поддержка регулярных выражений обеспечивает еще большую гибкость при работе с несколькими типами файлов одновременно.
Чтобы запретить роботам Googlebot, Bing и Baidu обход веб-сайта или специального каталога, используйте следующие правила:
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (googlebot|bingbot|Baiduspider) [NC]
RewriteRule .* - [R=403,L] Например, чтобы на всем сайте заблокировать поисковую индексацию форматов TXT, JPEG и PDF, добавьте следующий фрагмент в .htaccess:
<Files ~ "\.(txt|jpg|jpeg|pdf)$"> Header set X-Robots-Tag "noindex, nofollow" </FilesMatch>
5. Использование страницы с аутентификацией по имени пользователя и паролю
Вышеуказанные методы предотвратят появление вашего личного контента и документов в результатах поиска Google. Тем не менее, любые пользователи со ссылкой могут получить доступ к содержимому и файлам напрямую. В целях безопасности настоятельно рекомендуется настроить правильную аутентификацию с использованием имени пользователя и пароля, а также прав доступа к роли.
Например, страницы, содержащие личные профили сотрудников и конфиденциальные документы, доступ к которым не должен осуществляться анонимными пользователями, следует защищать с помощью аутентификации. Таким образом, даже когда пользователям каким-то образом удается найти страницы, им будет предложено ввести учетные данные, прежде чем они смогут увидеть содержимое.
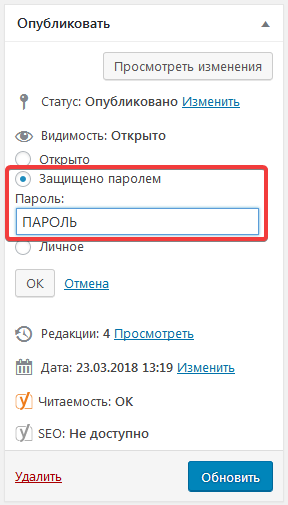
В WordPress для этого нужно:
- открыть страницу или запись на редактирование;
- в блоке Опубликовать найти опцию Видимость и установить ее значение Защищено паролем;
- задать пароль и нажать кнопку ОК;
- обновить страницу/запись (кнопка Обновить).
Google не любит неуникальный контент, поэтому не забывайте проверять уникальность страницы сайта онлайн.
Нажмите, пожалуйста, на одну из кнопок, чтобы узнать понравилась статья или нет.
А как наоборот избавится от
Установливалось на чистый движок поставил тему прописалось и невозможно найти где это прописано.
Та же проблема (только сайт существует давно). Ещё у WP недавно появилась другая “шляпа”: WP добавляет строку max-image-preview:large, которая тоже мешает индексации сайта поисковиками.
Здравствуйте! Мучался несколько часов в итоге всегда получал ошибку 500. Подскажите пожалуйста как сделать чтобы запрет был только для бота – Googlebot-Image и для папки – /wp-content/uploads/
RewriteEngine OnRewriteCond %{HTTP_USER_AGENT} (Googlebot-Image) [NC]
RewriteRule ./uploads/ - [R=403,L]
Пробовал так не работает. Или как сделать это командой:
Header set X-Robots-Tag "Googlebot-Image: noindex"Подскажите пожалуйста рабочий метод, спасибо большое!